ATT
ATT
 SoCalGas
SoCalGas
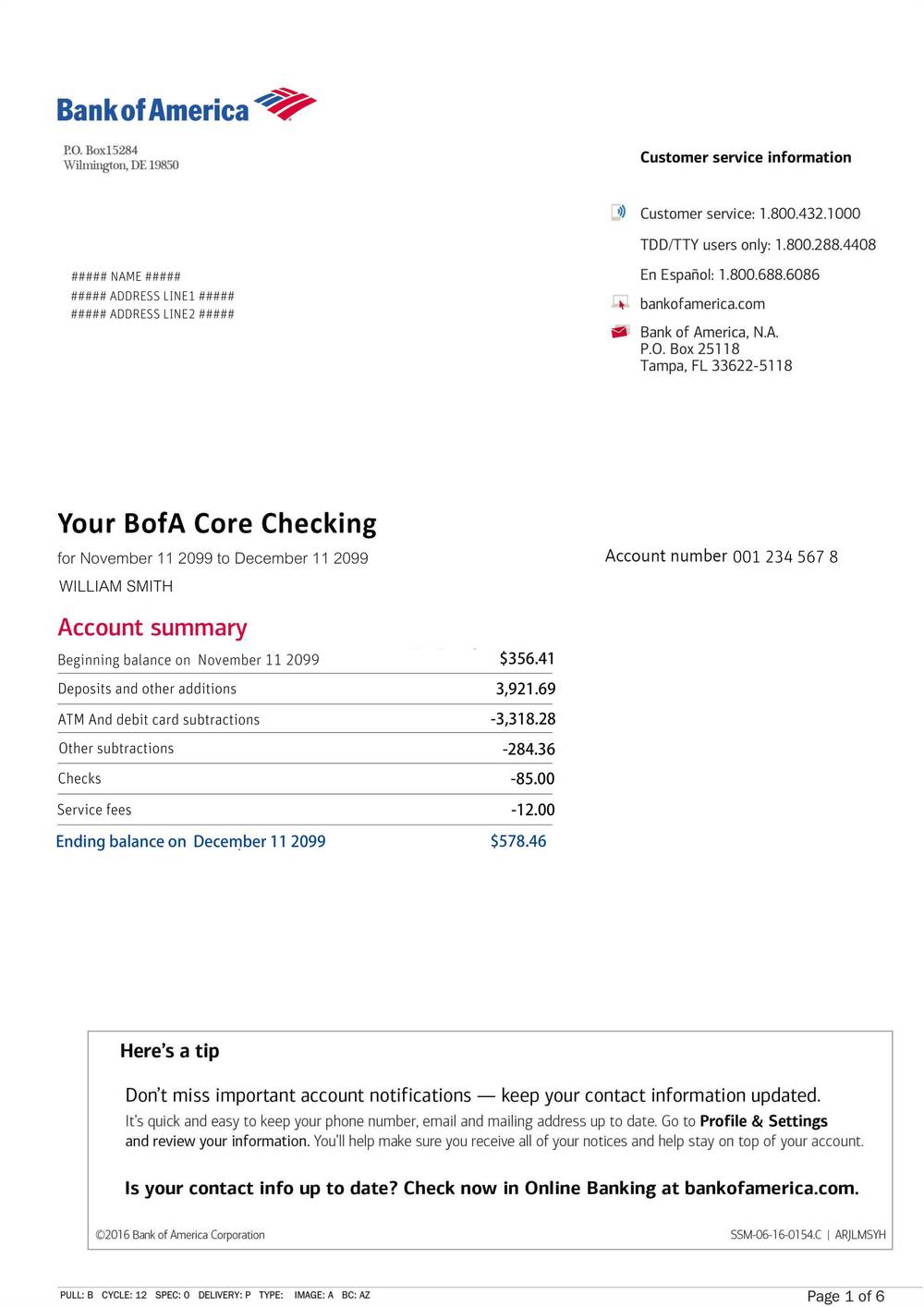
 Bank of America
Bank of America
 Chase
Chase
 Citibank
Citibank
 Tokyo Electric
Tokyo Electric
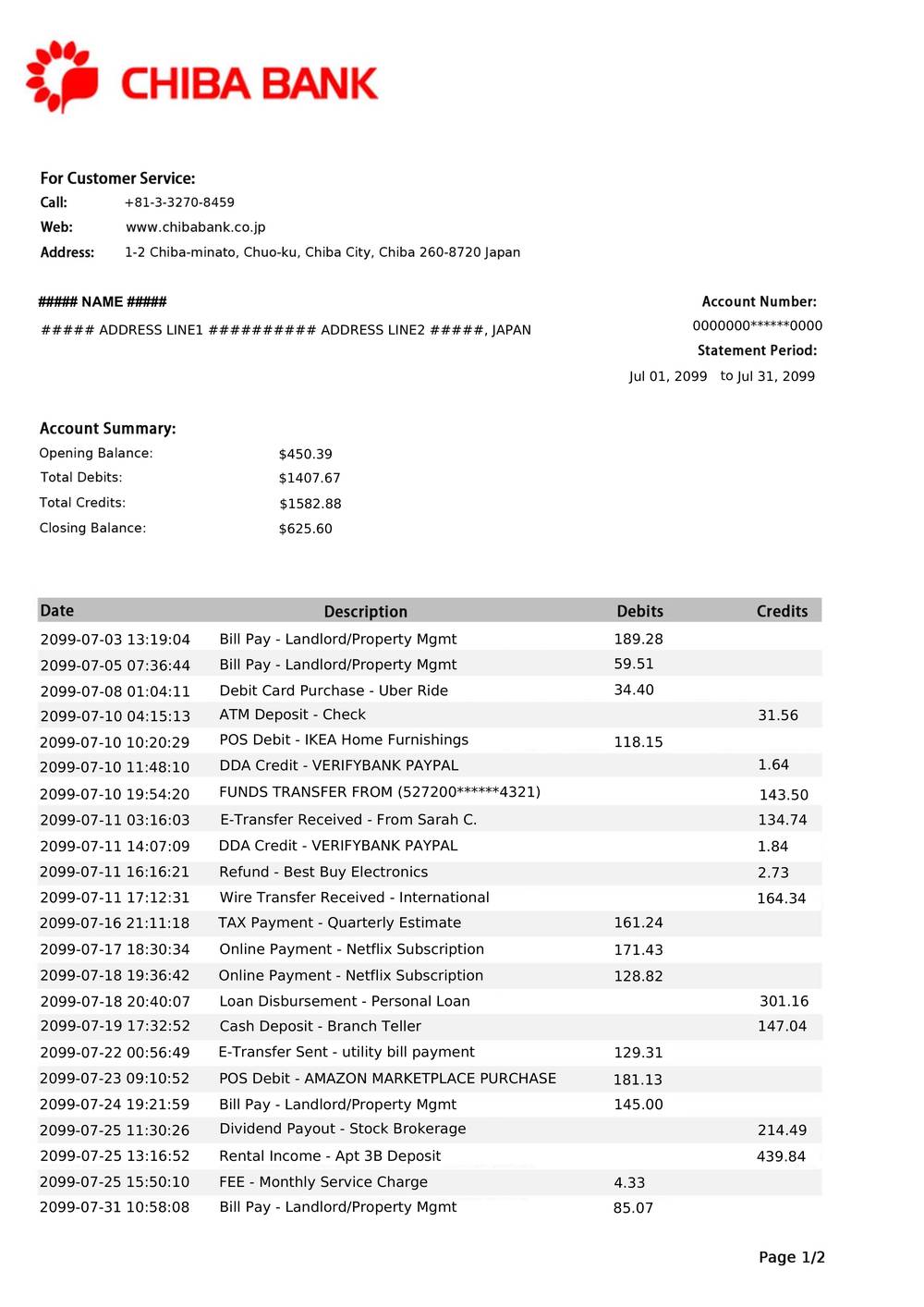
 CHIBABank
CHIBABank
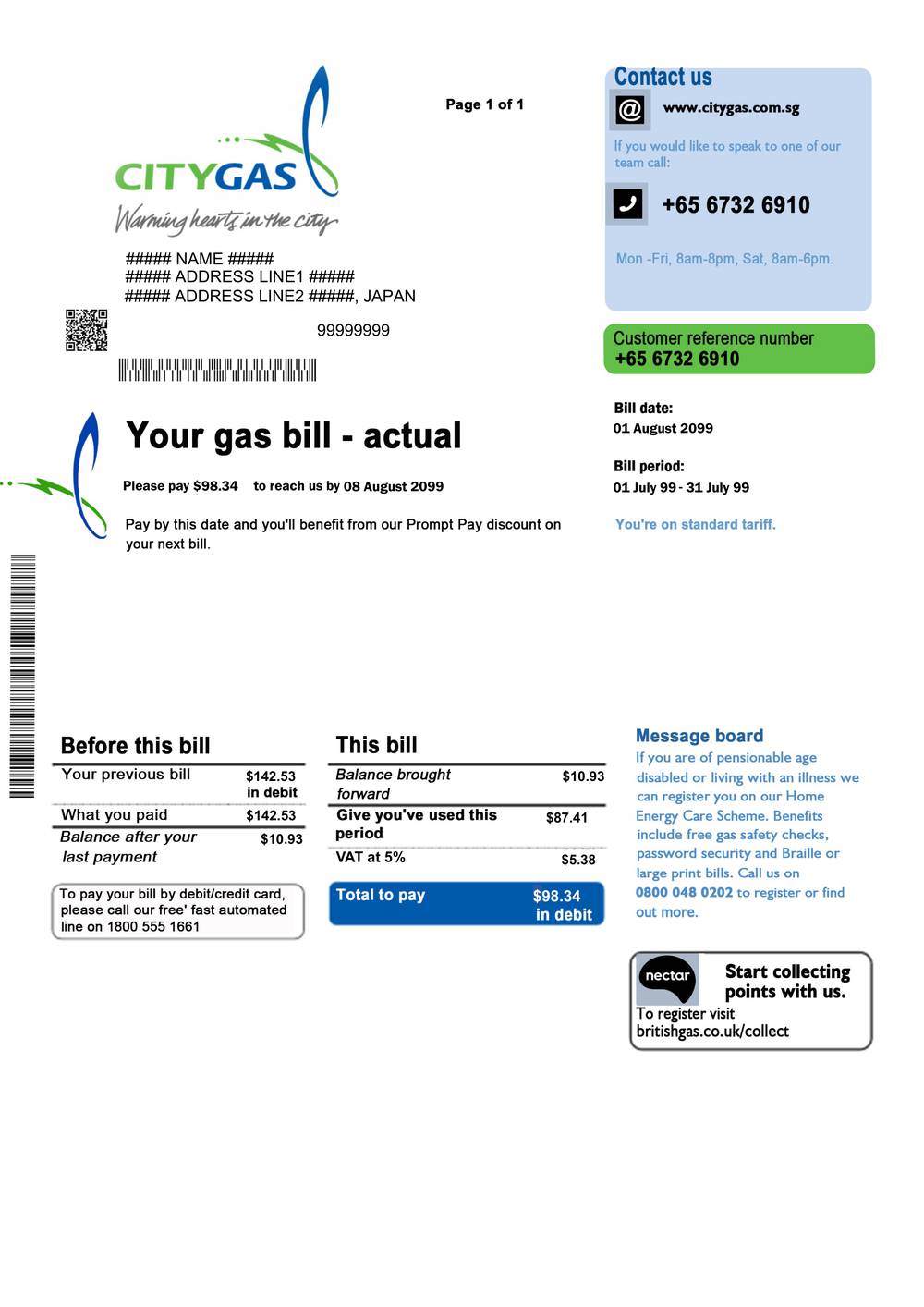
 Citygas
Citygas
Tags
One-Key Generate AT&T Utility Bill for Address Verification Testing
Telecommunication bills represent the most common form of Proof of Address globally. Use our advanced KYC generator to create highly realistic synthetic AT&T utility bills, perfect for training your AI to parse unstructured address data and complex billing cycles.
Decoding Complex Telecommunication Formats
Utility bills are notoriously difficult for automated KYC systems to process. They suffer from dynamic promotional inserts, varied page lengths, complex billing summaries, and inconsistent typography. AT&T formats, in particular, represent a massive portion of US-based utility submissions.
Our tool generates realistic synthetic AT&T invoices that mimic these real-world complexities. By utilizing this generator, your developers can train highly robust OCR models that learn to hunt down the critical "Service Address" or "Billing Address" regardless of the surrounding visual clutter, promotional graphics, or multi-line account summaries. This dramatically reduces the need for manual human review in your compliance department.
Practical KYC Automation Implementations
- Service vs. Billing Address Disambiguation: Train your AI to intelligently distinguish between a P.O. Box mailing address and the actual physical service installation address required for regulatory compliance.
- Low-Tier KYC Optimization: Optimize your system for consumer platforms (like crypto wallets or betting sites) that accept telecom utility bills as a primary form of Tier-1 identity verification.
- Fuzzy Matching Calibration: Test your backend's ability to fuzzy-match the extracted AT&T address against the user's self-reported registration data, accounting for common abbreviations (e.g., "St" vs "Street").
Advanced Document Engineering
Creating realistic Proof of Address (PoA) documents requires more than just pasting text onto a template. Our financial document generator employs advanced rendering techniques to ensure your OCR models receive the highest quality training data possible.
1. Dynamic Visual Noise & Artifacts
Real-world utility bills and bank statements are rarely perfectly crisp. To prevent your AI from overfitting to perfect digital PDFs, our generator can introduce slight visual artifacts, simulated scan noise, and realistic typography rendering. This ensures your extraction models perform well even on lower-quality user uploads.
2. Deep Metadata Simulation
Modern KYC pipelines don't just read the surface text; they inspect the file's digital integrity. Our generator embeds realistic creation metadata into the generated files. This is crucial for testing anti-fraud pipelines that check for software tampering or anomalous creation dates in user-submitted PoA documents.
3. Customizable Environmental Context
Users rarely scan their bills perfectly flat. Often, they take photos of paper bills lying on a desk. Our generator allows you to render the utility or banking statement against various contextual backgrounds. This is specifically designed to train your computer vision's bounding-box logic to accurately locate the document edges before OCR extraction begins.
Frequently Asked Questions
Q: Why are utility bills considered harder to parse than passports?
A: Passports follow strict ICAO standards with predictable data zones. Utility bills like AT&T have zero global standardization and change layouts frequently, making diverse synthetic training data crucial for AI adaptability.
Q: Does the one-key generate feature randomize the usage data?
A: Yes, it creates varied data points including data usage metrics, plan names, and tax calculations to ensure your OCR model learns to read the structure, rather than overfitting to a single static template.
Q: Is the generation of these documents compliant with data privacy laws?
A: Absolutely. All generated demographic and financial data is 100% synthetic and fictitious, ensuring your testing environment remains completely compliant with GDPR, CCPA, and other global privacy frameworks.