

Tags
Synthetischer Japan-Pass-Generator für APAC-KYC-Tests
Die Ausweitung Ihrer digitalen Dienste auf den asiatischen Markt erfordert stark lokalisierte Verifizierungsstrategien. Verwenden Sie unseren speziellen KYC-Generator, um hochpräzise japanische Passtestdaten zu erstellen. Dieses Tool wurde speziell entwickelt, um Ihre KI-Modelle in der komplexen Extraktion von Doppelbyte-Zeichen zu trainieren und die Einhaltung strenger regionaler APAC-Vorschriften sicherzustellen.

Beherrschung der Doppelbyte-Zeichen-OCR in Identitätssystemen
Japanische Ausweisdokumente stellen eine der größten Herausforderungen für westlich ausgerichtete Verifizierungssysteme dar. Die größte Hürde ist die nahtlose Integration von Romaji (lateinischen Schriftzeichen) neben den traditionellen Kanji, Hiragana und Katakana. Standard-OCR-Engines, die überwiegend auf lateinische Alphabete trainiert sind, halluzinieren oder interpretieren diese dichten typografischen Layouts häufig falsch, was zu hohen False Rejection Rates (FRR) beim Onboarding führt.
Dieser Generator erstellt strukturell präzise japanische Pässe, die das genaue Layout des japanischen Außenministeriums widerspiegeln. Durch die Verwendung dieses Tools können Entwickler die Fähigkeit ihrer OCR-Engines, komplexe Typografie, lokalisierte Namensformatierung und spezifische Datumsstrukturen (wie die Kalenderkonvertierungen der Kaiserzeit, sofern auf Ihre Backend-Logik anwendbar) verarbeiten können, ohne Genauigkeitseinbußen gründlich testen. Es bietet eine sichere und skalierbare Möglichkeit, Modelle für maschinelles Lernen für die japanische Bevölkerungsgruppe zu trainieren.
APAC-Lokalisierungs- und Extraktionstests
- Sprachübergreifende Datenextraktion: Trainieren Sie Ihre KI, um komplexe japanische Namen genau ihren obligatorischen MRZ-Romaji-Entsprechungen zuzuordnen und so die Datenkonsistenz in Ihrer gesamten Datenbank sicherzustellen.
- Regionale Compliance-Validierung: Vergleichen Sie Ihr System mit den strengen Datenverarbeitungs- und Verifizierungsanforderungen der japanischen Finanzdienstleistungsbehörde (FSA).
- High-Fidelity-Demografietraining: Generieren Sie verschiedene demografische Profile, um Rassen-, Alters- und regionale Vorurteile in Ihren biometrischen Gesichtserkennungsmodellen zu beseitigen.
Erweiterte Generatorfunktionen
Über spezifische regionale Layouts hinaus wird unser KYC-Generator von einer robusten Engine angetrieben, die darauf ausgelegt ist, äußerst realistische, standardkonforme Testartefakte zu erzeugen. Wir verstehen, dass moderne Verifizierungssysteme nicht nur den Text betrachten, sondern auch den digitalen Fußabdruck und die Strukturmathematik des Dokuments analysieren.
1. Kryptografisch gültige MRZ-Generierung
Für Dokumente, die dies unterstützen (wie Reisepässe und bestimmte Personalausweise), generiert unser System nicht nur zufällige Zeichen. Es nutzt den offiziellen ICAO 9303-Algorithmus, um mathematisch korrekte maschinenlesbare Zonen (MRZ) zu berechnen. Dadurch wird sichergestellt, dass Ihre Backend-Prüfsummenvalidierungen während der automatisierten Tests erfolgreich verlaufen.
2. Authentische EXIF-Metadaten-Injektion
Betrugserkennungssysteme analysieren häufig Fotometadaten, um manipulierte Bilder zu erkennen. Unser Generator fügt automatisch realistische EXIF-Daten (einschließlich simulierter Kameramodelle, Brennweiten und GPS-Koordinaten, falls erforderlich) in die Ausgabedateien ein und hilft Ihnen so, die Deep-File-Inspektionsroutinen Ihres Systems zu testen.
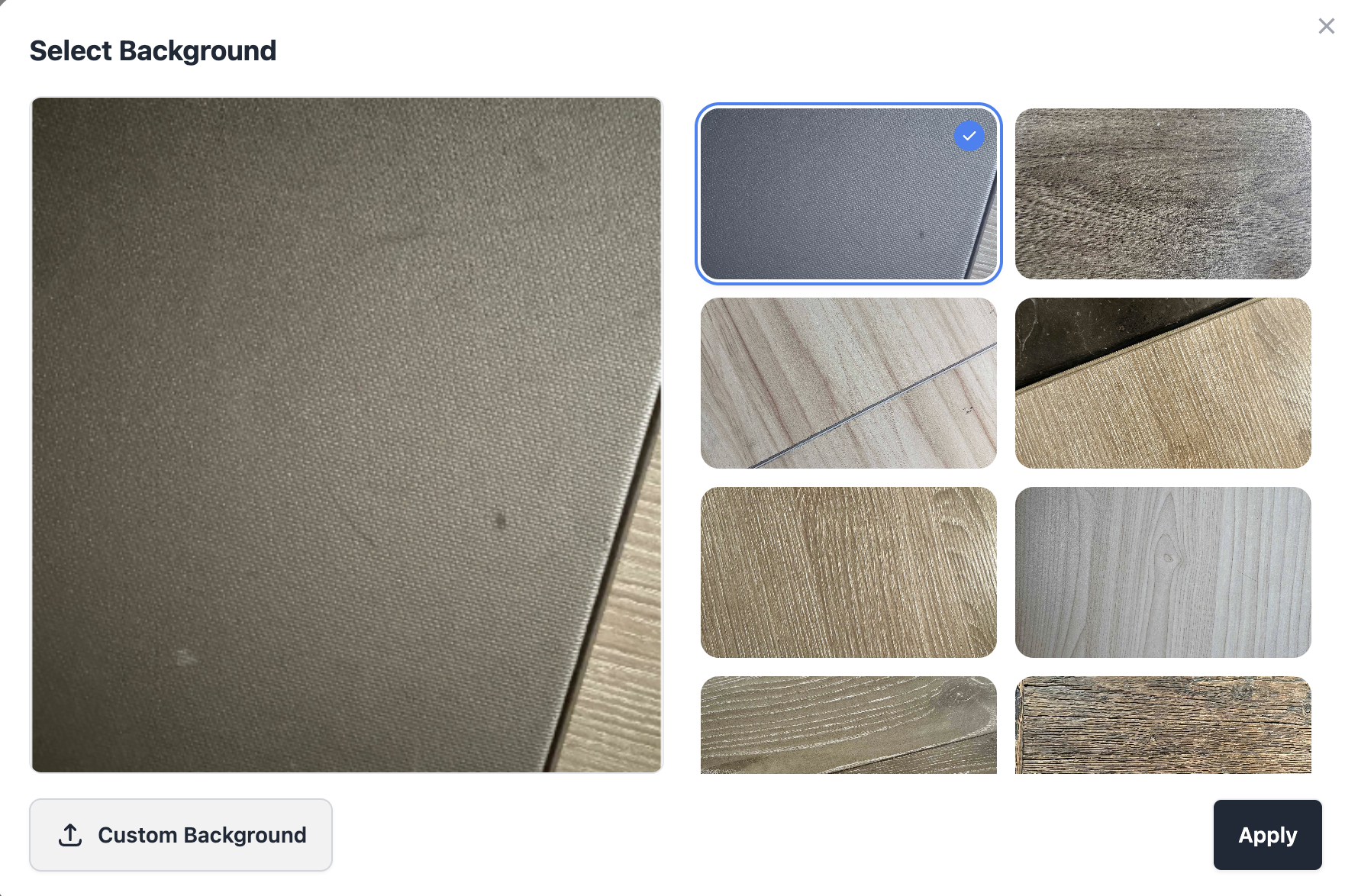
3. Anpassbare Umwelthintergründe
Um Ihre Algorithmen zur Kantenerkennung und zum Zuschneiden von Dokumenten zu trainieren, sollten Dokumente nicht auf einer flachen weißen Leinwand präsentiert werden. Mit unserem Tool können Sie die generierte ID auf verschiedene realistische Hintergründe (Holztische, Bettlaken, Händchenhalten) legen, um das Hochladen echter Benutzerfotos zu simulieren.
Häufig gestellte Fragen
F: Kann dieser Generator die OCR-Genauigkeit für asiatische Zeichen wirklich verbessern?
A: Ja. Die größte Hürde beim OCR-Training für japanische Ausweise ist der Mangel an vielfältigen Trainingsdaten. Unser Tool bietet unbegrenzte Variationen japanischer Namen und Layouts, um dieses Datendefizit zu beheben.
F: Entspricht die generierte MRZ den japanischen Ausstellungsstandards?
A: Das Tool hält sich strikt an die ICAO 9303-Standards und spiegelt die genaue algorithmische Struktur und den Ländercode („JPN“) wider, die von der japanischen Regierung verwendet werden.
F: Warum synthetische japanische Pässe anstelle echter anonymisierter Daten verwenden?
A: Der Erwerb echter Testdaten ist in Japan aufgrund strenger Datenschutzgesetze wie dem Gesetz zum Schutz personenbezogener Daten (APPI) äußerst schwierig und rechtlich riskant. Die synthetische Erzeugung ist die einzige vollständig gesetzeskonforme Möglichkeit zur Skalierung von Tests.




