Tokyo Electric
Tokyo Electric
 ATT
ATT
 SoCalGas
SoCalGas
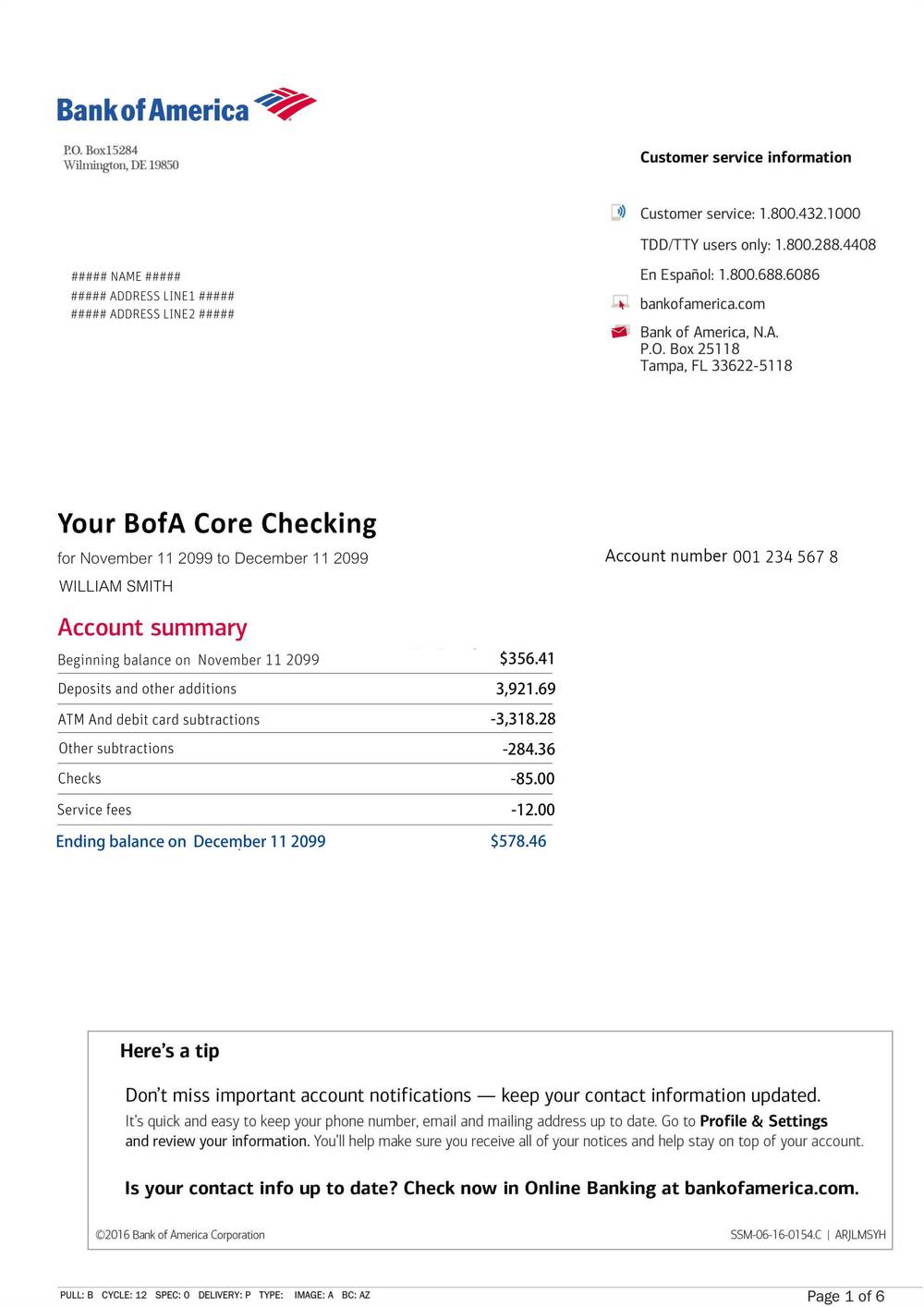
 Bank of America
Bank of America
 Chase
Chase
 Citibank
Citibank
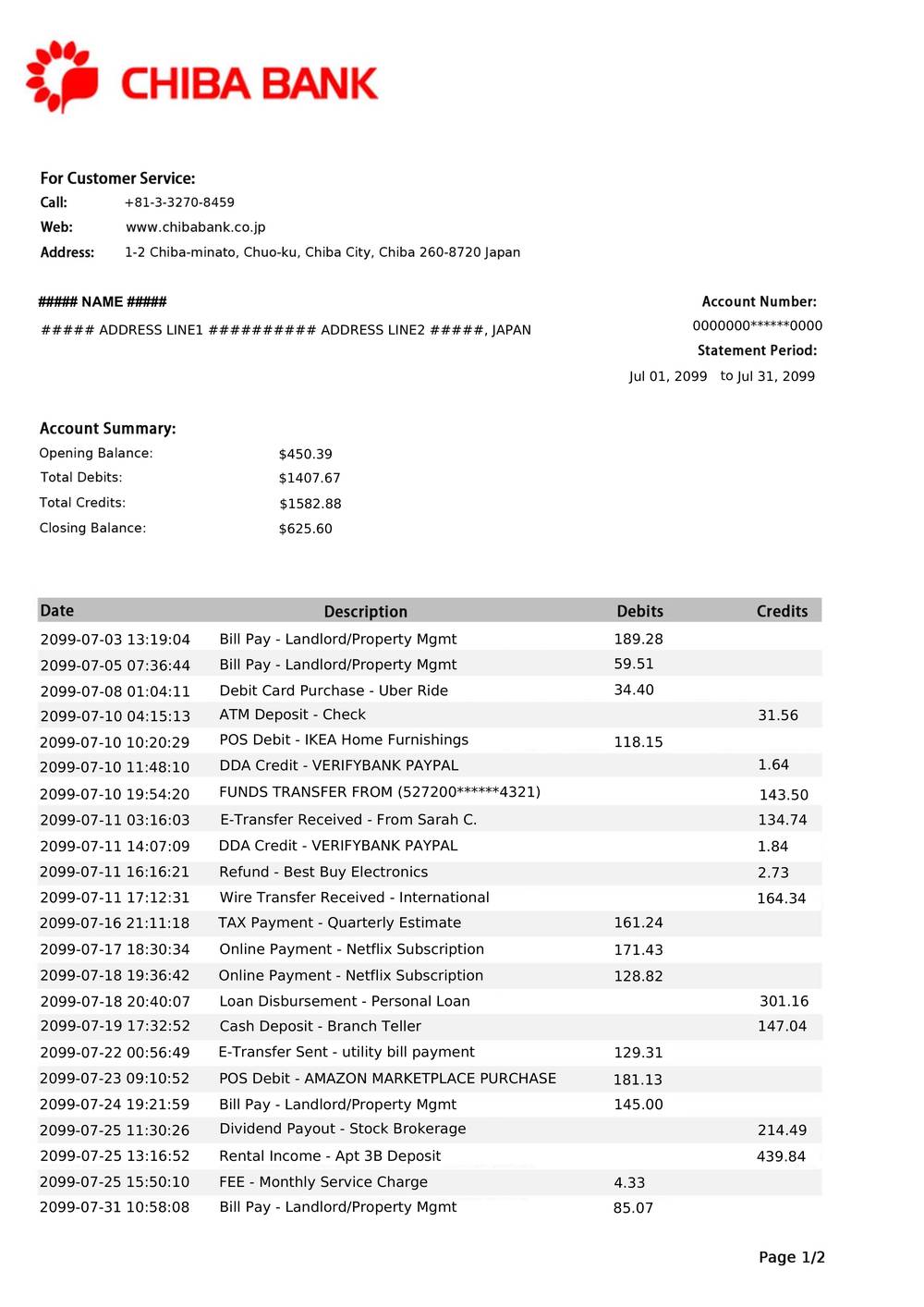
 CHIBABank
CHIBABank
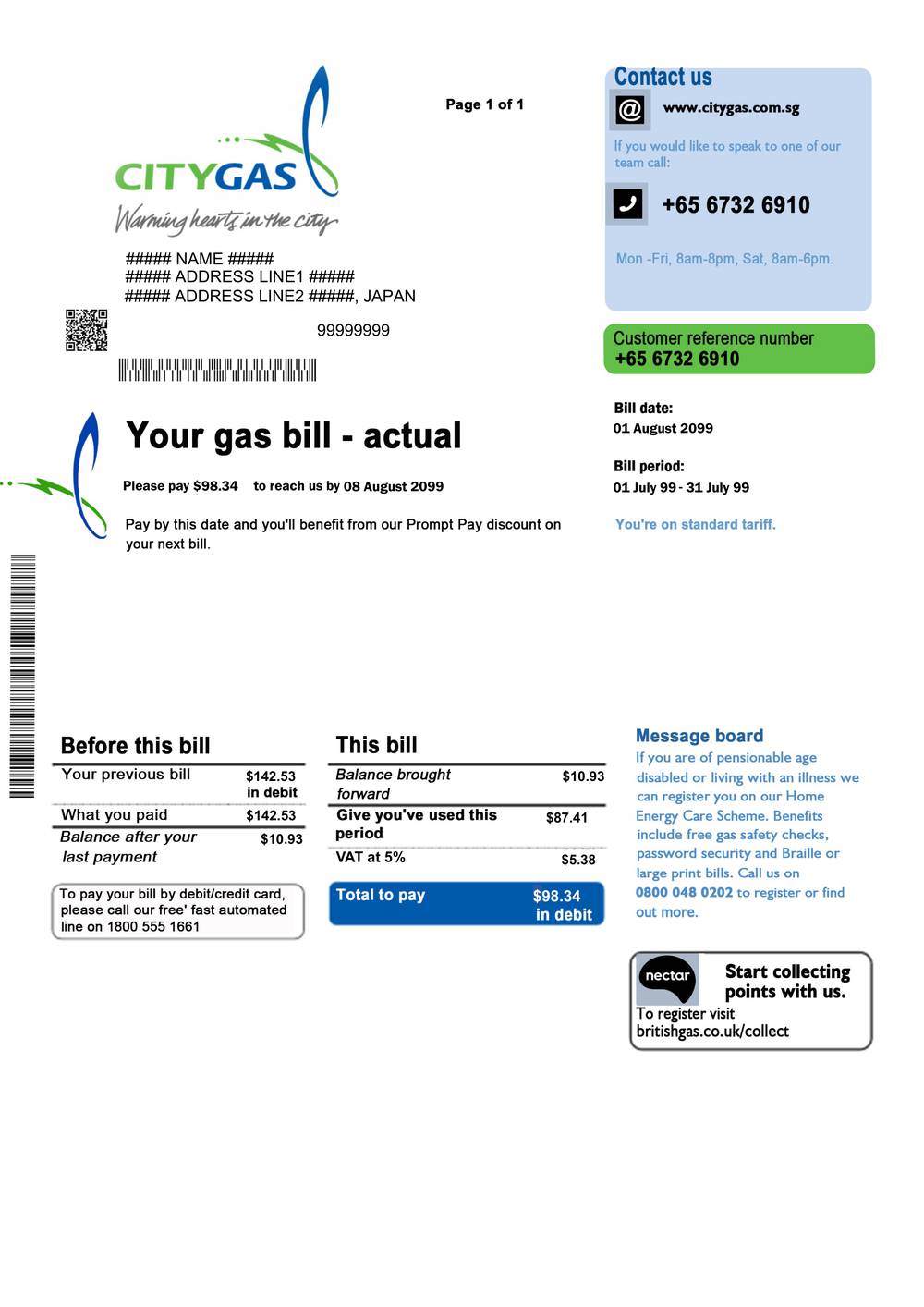
 Citygas
Citygas
Tags
Synthetic Tokyo Electric Generator for Address Verification
Optimize your Proof of Address (PoA) extraction logic with precision. Our specialized KYC generator produces standardized Tokyo Electric documents to benchmark your automated compliance workflows and train unstructured data parsers.
Mastering Unstructured Data Extraction
Extracting accurate residential address data from utility and banking documents is widely considered a major hurdle in automated KYC processing. Unlike structured IDs, financial and utility bills vary wildly in layout, font choices, and data density.
Our generator solves this by creating highly realistic Tokyo Electric synthetic templates. It provides your OCR and machine learning models with the diverse, high-quality visual data needed to learn precise address bounding and text extraction. By training your systems on these specific layouts, you can significantly reduce the False Rejection Rate (FRR) of legitimate users who submit complex or cluttered billing documents during onboarding.
PoA Testing Advantages
- Address Parsing Accuracy: Train computer vision models to intelligently locate the user's residential address amid irrelevant transactional data, marketing inserts, or account summaries.
- Temporal Validation Testing: Generate documents with highly specific historical issue dates to test your system's temporal compliance rules (e.g., ensuring documents must be under 3 months old).
- Vendor API Benchmarking: Objectively measure the performance, speed, and accuracy of third-party address verification APIs using standardized, repeatable synthetic inputs.
Advanced Document Engineering
Creating realistic Proof of Address (PoA) documents requires more than just pasting text onto a template. Our financial document generator employs advanced rendering techniques to ensure your OCR models receive the highest quality training data possible.
1. Dynamic Visual Noise & Artifacts
Real-world utility bills and bank statements are rarely perfectly crisp. To prevent your AI from overfitting to perfect digital PDFs, our generator can introduce slight visual artifacts, simulated scan noise, and realistic typography rendering. This ensures your extraction models perform well even on lower-quality user uploads.
2. Deep Metadata Simulation
Modern KYC pipelines don't just read the surface text; they inspect the file's digital integrity. Our generator embeds realistic creation metadata into the generated files. This is crucial for testing anti-fraud pipelines that check for software tampering or anomalous creation dates in user-submitted PoA documents.
3. Customizable Environmental Context
Users rarely scan their bills perfectly flat. Often, they take photos of paper bills lying on a desk. Our generator allows you to render the utility or banking statement against various contextual backgrounds. This is specifically designed to train your computer vision's bounding-box logic to accurately locate the document edges before OCR extraction begins.
Frequently Asked Questions
Q: Why use synthetic bills instead of real, anonymized documents for testing?
A: Real bills almost always contain lingering sensitive PII. Using completely synthetic data ensures absolute compliance with data protection regulations like GDPR and CCPA while testing your systems.
Q: Does the generator create realistic financial line items?
A: Yes, the generator intelligently populates the document with structured, realistic visual noise (like randomized transactions or utility usage graphs) to properly train AI extraction algorithms to ignore irrelevant data.
Q: Is this tool suitable for crypto exchange KYC requirements?
A: Absolutely. It provides the exact proof-of-address document types mandated by global financial regulators for crypto exchanges to verify user residency.